百度百科解析
爬取basic info
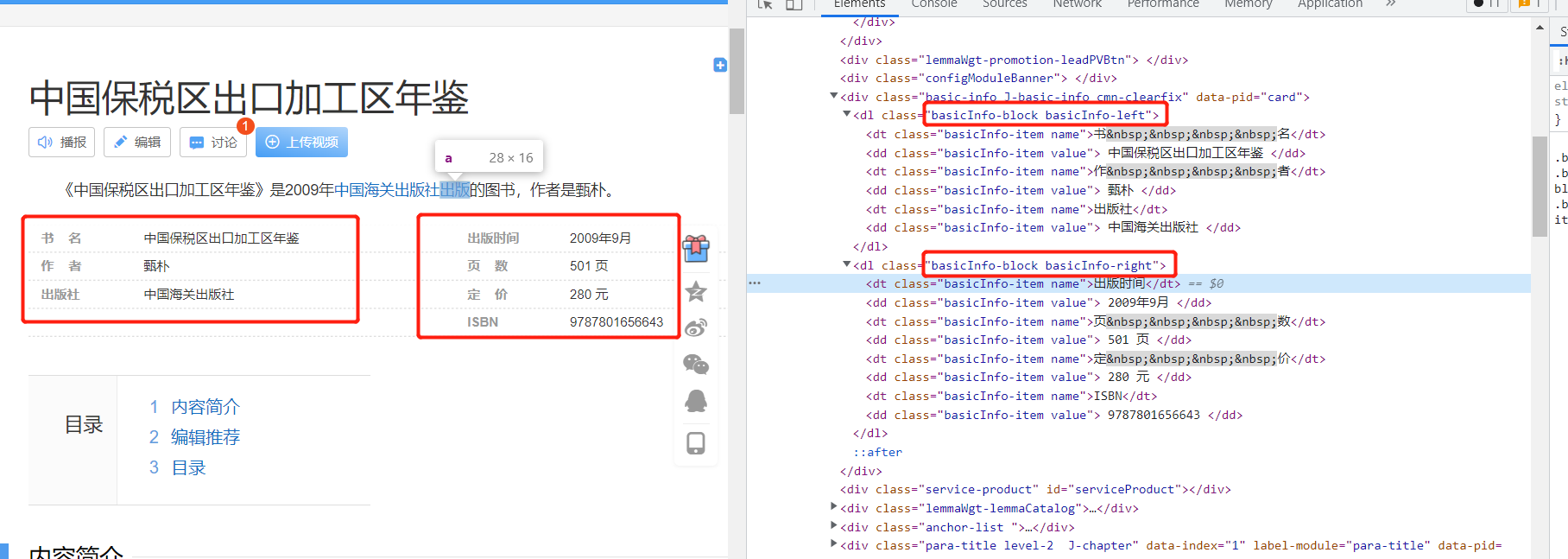 image-20220313100101027
image-20220313100101027
<dt>标签存放属性名,<dd>标签存放内容;<dt>和<dd>一一对应的关系。
如果dt和dd数量不相等,这是严重的错误,可能会导致数据的移位。程序在遇到这种情况时,这部分的信息不会被爬取,get_basicInfo() 返回 [ ]。
def get_basicInfo(class_name: str):
# basicInfo-block basicInfo-left
# basicInfo-block basicInfo-right
basicInfo = soup.find_all(class_=class_name)
if check(basicInfo, class_name):
basicInfo_tag = basicInfo[0]
else:
return False
res = []
names = [t.get_text().strip() for t in basicInfo_tag.find_all(class_='basicInfo-item name')]
values = [t.get_text().strip() for t in basicInfo_tag.find_all(class_='basicInfo-item value')]
name_num = len(names)
value_num = len(values)
if name_num == value_num:
z = zip(names, values)
for name, value in z:
res.append(name + ":" + value)
return res
else:
print("严重错误")
return []
basicInfo-block basicInfo-left和basicInfo-block basicInfo-right,调用get_basicInfo完成信息抽取。
get_basicInfo()
异常检查,统计
basicInfo-item name和basicInfo-item value的个数,若不相等则返回[],输出警高 提示用户;将name和value,
zip到一起。
爬取目录
爬取目录结构
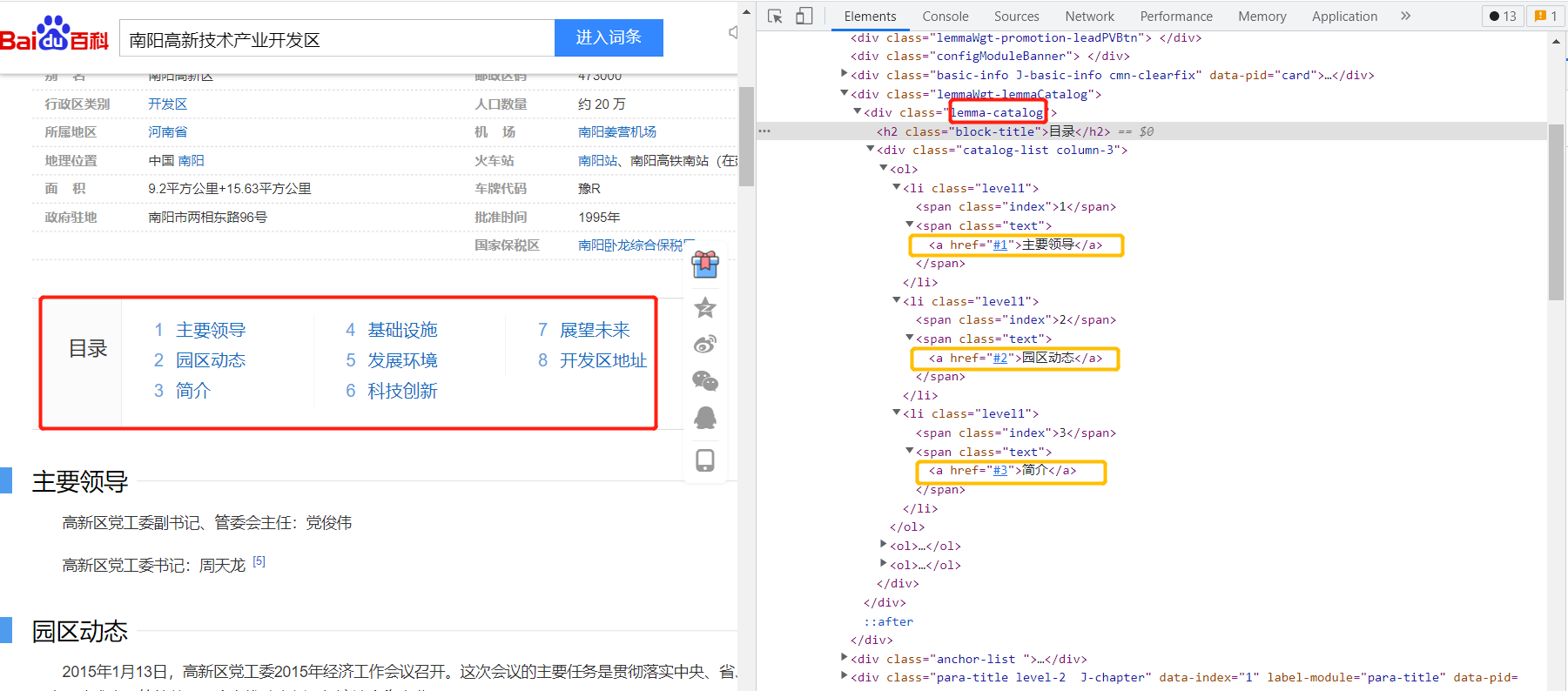 image-20220313102615896
image-20220313102615896
目录存放在class='lemma-catalog'的div中,目录标题存放在<a>标签中,并且这个标签有href属性。
find_all('div', class_='lemma-catalog'),拿到存放目录的div在
div中,查找带有href属性的<a>标签,使用的函数是find_all(a_has_href);
关于find_all()的详细介绍,点击查看官方文档;
def a_has_href(tag: bs4.element.Tag):
return tag.has_attr('href') and tag.name == 'a'
def get_lemma_catalog_num(soup: bs4.BeautifulSoup) -> [int, List]:
# lemma-catalog
lemma_catalog = soup.find_all('div', class_='lemma-catalog')
if check(lemma_catalog, 'lemma-catalog'):
lemma = [t.string for t in lemma_catalog[0].find_all(a_has_href)]
return len(lemma), lemma
return 0, []
爬取目录内容
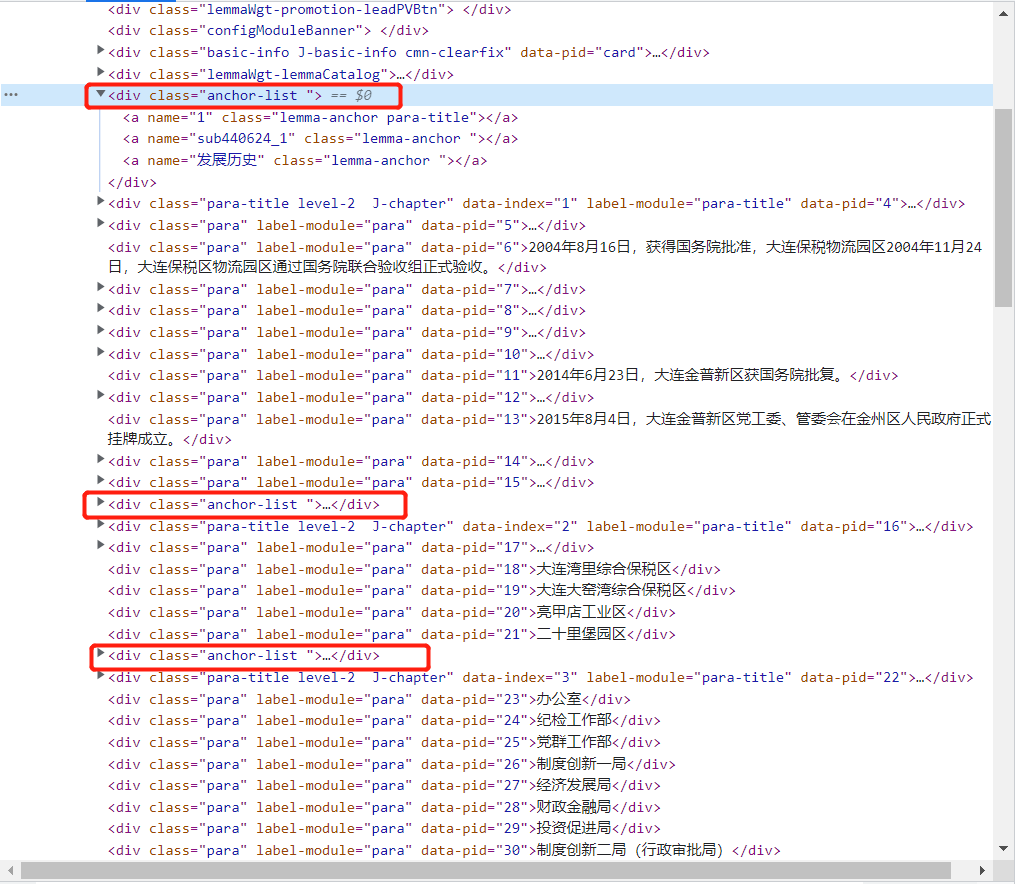 image-20220313172233711
image-20220313172233711
每个目录的标题,都放在<div class="anchor-list">...</div>中,标题节点后的便是目录的内容;
先用find_all()找到第一个
<div class="anchor-list">...</div>;接着遍历,它的兄弟节点,用
get_text()抽取信息,这都是当前目录节点的内容;直到遇到下一个
<div class="anchor-list">...</div>,那么上个目录内容抽取结束,下一个目录内容抽取开始;
关于兄弟节点的用法,点击查看文档
num = xxx # 目录节点个数
cnt = 0
ans = []
tmp = []
for sibling in anchor.next_siblings:
tmp.append(sibling.get_text().strip().replace("\n编辑\n\n播报", ""))
if is_div_anchor_list(sibling):
cnt += 1
ans.append("".join(tmp))
tmp = []
if cnt == num:
break
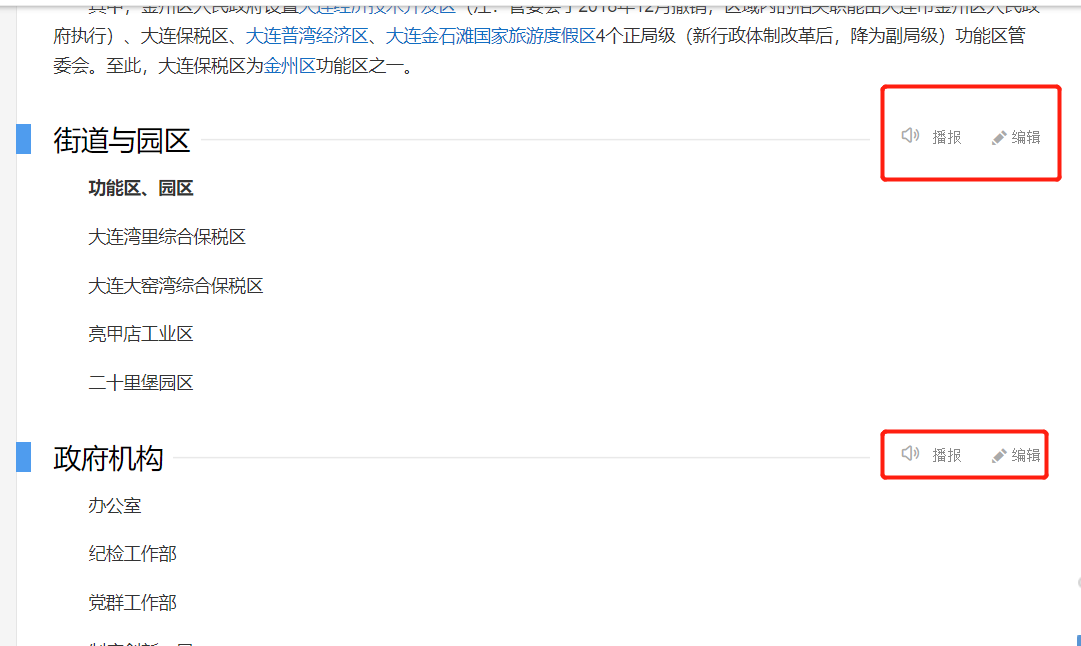 image-20220313173254758
image-20220313173254758
每个内容之间的提示信息,比如:播报和提示,使用replace()对字符串进行替换;
sibling.get_text().strip().replace("\n编辑\n\n播报", "")